Estimation of Appearance and Occupancy Information in Bird’s Eye View from Surround Monocular Images
Abstract
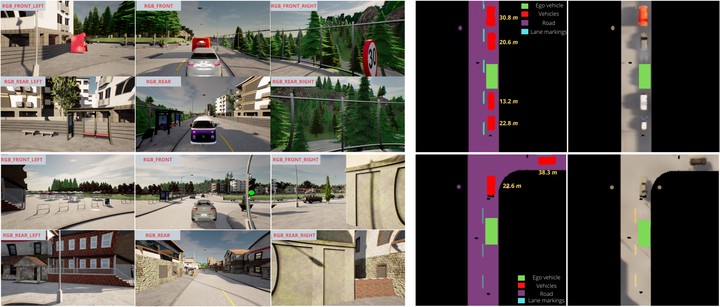
Autonomous driving requires efficient reasoning about the location and appearance of the different agents in the scene, which aids in downstream tasks such as object detection, object tracking, and path planning. The past few years have witnessed a surge in approaches that combine the different taskbased modules of the classic self-driving stack into an End-toEnd(E2E) trainable learning system. These approaches replace perception, prediction, and sensor fusion modules with a single contiguous module with shared latent space embedding, from which one extracts a human-interpretable representation of the scene. One of the most popular representations is the Birds-eye View (BEV), which expresses the location of different traffic participants in the ego vehicle frame from a top-down view. However, a BEV does not capture the chromatic appearance information of the participants. To overcome this limitation, we propose a novel representation that captures various traffic participants appearance and occupancy information from an array of monocular cameras covering 360 deg field of view (FOV). We use a learned image embedding of all camera images to generate a BEV of the scene at any instant that captures both appearance and occupancy of the scene, which can aid in downstream tasks such as object tracking and executing language-based commands. We test the efficacy of our approach on synthetic dataset generated from CARLA.
Udit Singh Parihar
Computer Vision, DL and SLAM Research Engineer
My research interests include the intersection of 3D Computer Vision, Deep Learning, and SLAM.